It is not uncommon that I am asked the following question during public talks: “Does innovation happen in large pharmaceutical companies?” Sometimes, the question is just a critical comment, disguised as a question: “Large pharma does not innovate, they just conduct clinical trials and drive up the cost of drugs. Right?” Other times the questions are more thoughtful: “As an academic, I don’t see what happens in industry. Can you describe examples of innovation driven out of large pharma?”
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
At the risk of sounding defensive, here are some answers to the “pharma innovation” question. I know there are many more, and I invite readers to share their examples. Admittedly, the examples are biased towards examples at Merck, but that is just because I know these examples better.
First, the past couple of weeks have been particularly good for industry scientists. These recent examples provide objective evidence to answer the pharma innovation question.
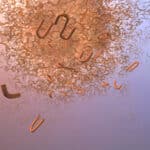
(a) 2015 Nobel Prizein Physiology or Medicine. Former Merck scientist Dr. William Campbell was awarded the Nobel Prize for the discovery of an antiparasitic agent used to treat river blindness in places like Latin America, Africa and Yemen.…
I say article of the week, but I have been lazy this summer (or maybe just consumed by other things). My last “article of the week” was in May and my last Plengegen blog post was over a month ago!
By now everyone knows the PCSK9 story. Human genetics identified the target; functional work in mouse and human cells led to a mechanistic understanding of PCSK9’s role in LDL receptor recycling; therapeutic modulation was shown to lower LDL cholesterol in clinical trials; and the FDA approved drugs based on LDL lowering, with outcome trials underway to demonstrate (presumably) cardiovascular benefit. What the story highlights is that a mechanistic understanding of causal pathways in human disease is key to the success of translating targets into therapies. Further, the PCSK9 story underscores the importance of a simple biomarker (LDL cholesterol) to measure a complex causal pathway in a clinical trial.
If you could pick three innovations that would revolutionize drug discovery in the next 10-20 years, what would they be?
I found myself thinking about this question during a recent family vacation to Italy. I was visiting the Galileo Museum, marveling at the state of knowledge during the 1400-1600’s. The debate over planetary orbits seem so obvious now, but the disagreement between church and science led to Galileo’s imprisonment in 1633.
So what is it today that will seem so obvious to our children and grandchildren…and generations beyond? Let me offer a few ideas related to drug discovery, and hope that others will add their own. I am not sure if my ideas are grounded in reality, but that is part of the fun of the game. In addition, “The best way to predict the future is to invent it.”
To start, let me remind readers of this blog that I believe that the three major challenges to efficient drug discovery are picking the right targets, developing the right biomarkers to enable proof-of-concept (POC) studies, and testing therapeutic hypotheses in humans as quickly and safely as possible. Thus, the future needs to address these three challenges.
I attended the Mendelian randomization meeting in Bristol, UK this past week (link to the program’s oral abstracts here). The meeting was timed with the release of a number of articles in the International Journal of Epidemiology (current issue here, Volume 44, No. 2 April 2015 TOC here). This blog is a brief synopsis of the meeting – with a focus on human genetics and drug discovery. The blog includes links to several slide decks, as well as references to several published reviews and studies.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
Several speakers, including Lon Cardon from GSK, gave overview talks on how Mendelian randomization can be applied to pharmaceutical development. In my overview, I described important guiding principles for successful drug discovery (link to my slides here), and how Mendelian randomization (MR) is applied within this framework. In particular, I emphasized the role of establishing causality in the human system: MR is a powerful tool to pick targets by estimating safety and efficacy (i.e., genotype-phenotype dose-response curves) at the time of target identification and validation; MR is effective at picking biomarkers for target modulation; and MR provides quantitative modeling of clinical proof-of-concept (POC) studies.…
This week I want to focus on the role of biomarkers in drug discovery and development, which is one of the three pillars of a successful translational medicine program (see slide deck here). The focus is on Alzheimer’s disease, based on recent articles published in JAMA. At the end of the blog you will find postings for new biomarker positions in Merck’s Translational Medicine Department.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
Before I start, I want to point to a few blogs that provide counterarguments to some of the optimistic opinions expressed in this blog. The first is David Dobb’s negative view on big data (here); the second on Larry Husten’s concerns about conflicts of interest between academics and industry, as it relates to a recent NEJM series (here). I will not comment further, but it is worth pointing readers to these blogs and related blogs for a balanced view on complicated topics.
I have expressed the strong opinion that what ails drug discovery and development is that we pick the wrong targets, don’t develop robust biomarkers, and we don’t test therapeutic hypotheses quickly enough in clinical trials.…
The primary purpose of this blog is to recruit clinical scientists into our new Translational Medicine department at Merck (job postings at the end). However, I hope that the content goes beyond a marketing trick and provides substance as to why translational medicine is crucial in drug discovery and development. Moreover, I have embedded recent examples of translational medicine in action, so read on!
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
There is a strong need to recruit clinical scientists into an ecosystem to develop innovative therapies that make a genuine difference in patients. This ecosystem requires those willing to toil away at fundamental biological problems; those committed to converting biological observations into testable therapeutic hypotheses in humans; and those who develop therapies and gain approval from regulatory agencies throughout the world. The first step is largely done in academic settings, and the other two steps largely done in the biopharmaceutical industry…although I am sure there are many who would disagree with this gross generalization!
The term “Translational Medicine” has been broadly used to describe the second step, thereby bridging the Valley of Death between the first and third steps.…
Many of you are probably fully aware of how immuno-oncology is changing cancer treatment. Ken Burns highlighted immunotherapy in his recent PBS series, “Cancer: The Emperor of All Maladies” (video link here). Forbes’ Matthew Herper, BBC and others have written extensively about it, too (here, here). More recently, Genome Magazine had a feature article on the history of immunotherapy (here). As the article states: “The promise of immunotherapy is startling in its simplicity: With a little help from cancer doctors, the patients will cure themselves.”
The key word here is “cure”. Cure!
The purpose of this blog is two-fold: (1) introduce geneticists and genomicists to cancer immunotherapy, if they have not thought about it before, and (2) highlight a recent Science publication by Elaine Mardis, Gerald Linette, and colleagues at WashU (here), with an accompanying News & Views article in Nature (here).
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
Cancer immunotherapy is really cool! As a former practicing rheumatologist at Brigham and Women’s Hospital, I had thought about the role of neoantigens in autoimmunity for many years.…
I admit upfront that this is a self-serving blog, as it promotes a manuscript for which I was directly involved. But I do think it represents a very nice example of the role of human genetics for drug discovery. The concept, which I have discussed before (including my last blog), is that there is a four-step process for progressing from a human genetic discovery to a new target for a drug screen. A slide deck describing these steps and applying them to the findings from the PLoS One manuscript can be found here, which I hope is valuable for those interested in the topic of genetics and drug discovery.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer. However, the PLoS One study was performed while I was still in academics at BWH/Harvard/Broad.]
Before I provide a summary of the study, I would like to highlight a few recent news stories that highlight that the world thinks this type of information is valuable. First, the state of California is investing US $3-million in a precision medicine project that links genetics and medical records to develop new therapies and diagnostics (here, here).…
There was an eruption in Iceland last week. No, this was not another volcanic eruption. Rather, there was a seismic release of human genetic data that provides a glimpse into the future of drug discovery. The studies were published in Nature Genetics (the issue’s Table of Contents can be found here), with insightful commentary from Carl Zimmer / New York Times (here), Matthew Herper / Forbes (here), and others (here, here).
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
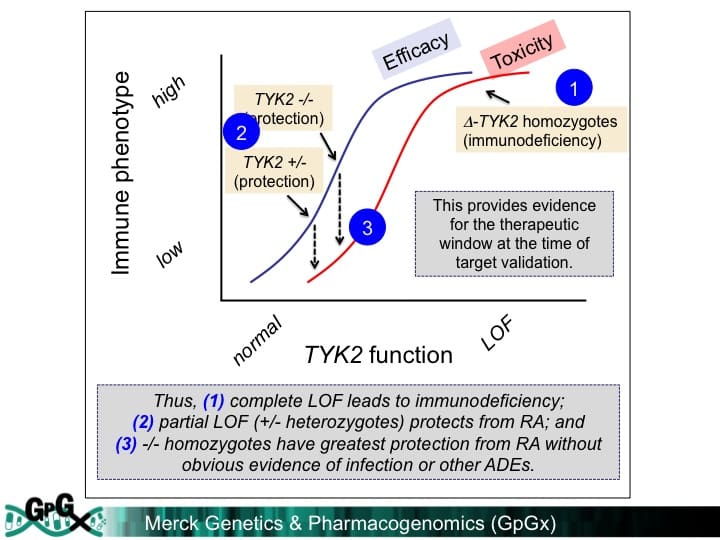
As I have commented before, human genetics represent a very powerful approach to identify new drug targets (see here, here). I have articulated a 4-step process (see slide #5 from this deck): (1) select a phenotype that is relevant for drug discovery; (2) identify a series of genetic variants (or “alleles”) that is associated with the phenotype; (3) assess the biological function of phenotype-associated alleles; and (4) determine if those same alleles are associated with other phenotypes that may be considered adverse drug events.
There is an important assumption about this model: genes with an “allelic series” will be identified from large-scale genetic studies, and these phenotype-associated alleles will serve as an estimate of function-phenotype dose-response curves.…
My overly simplistic vision of the way to transform drug discovery is to (1) pick targets based on causal human biology (e.g., experiments of nature, especially human genetics), (2) develop drugs that recapitulate the biology of the human experiments of nature (e.g., therapeutic inhibitors of proteins), (3) develop biomarkers that measure target modulation in humans, and (4) test therapeutic hypotheses in humans as safely and efficiently as possible.
Thus, one of my favorite themes is “causal human biology”. The word “causal” is key: it means that there is clear evidence between the cause-effect relationship of target perturbation in humans and a desired effect on human physiology. Human genetics represent one way to get at causal human biology, and in my last blog I highlighted recent examples outside of human genetics.
I am constantly scanning the literature to find examples that support or refute this model, as I predict that a discipline portfolio of projects based on causal human biology will be more successful than past efforts by the pharmaceutical industry.
This week I have selected two articles on genetics/genomics in drug discovery that provide further support of this model. [Disclaimer: the first study was funded by Merck, my employer.]…
Oliver Sacks has terminal cancer. If you have not yet read his heart-warming Op-Ed piece in the New York Times and if you only have five-minutes to spare, then I suggest you read his essay rather than this blog about “experiments of nature” in drug discovery. In his essay, Dr. Sacks concludes with the poignant sentence: “Above all, I have been a sentient being, a thinking animal, on this beautiful planet, and that in itself has been an enormous privilege and adventure.”
So why do I blog, tweet, etc. given the potential risk? I enjoy the public exchange of ideas because, as Dr. Sacks write, that is the essence of our “sentient being”. I enjoy a network of inter-related ideas for which I can create unique connections.…
ICYMI – the New England Patriots won the Super Bowl. How they did it was remarkable, and improbable. To introduce this week’s articles on human genetics and drug discovery, I want to focus on the interception of Russell Wilson by Malcolm Butler. If the pass is on-target, Seahawks win. By now you know the story: the pass was off-target, and the Seahawks lost.
[A lot has been said about Pete Carroll’s play call (see FiveThirtyEight.com statistical analysis here), but that is irrelevant for this discussion.]
As in football, on-target vs off-target events are highly relevant in drug discovery. Think about what it takes to develop a drug, and how “drug accuracy” (like passing accuracy) can make-or-break a development program. First, you start with a target. Next, you develop a drug against that target. Then, you test the target in pre-clinical models to make sure it is doing what you think it should do. And finally, you take the drug into humans to see if it has an adequate therapeutic index (i.e., is safe and effective).
All along the way you assess whether the therapeutic molecule is selectively engaging and modulating the desired target, and not acting more promiscuously on other targets in the system.…
Imagine you live in Boston or New York. It is Monday January 26, 2015. You are watching headlines of an impending blizzard, trying to figure out the truth about the weather for the next day. You find that the National Weather Service has a cool online tool – experimental probabilistic snow forecast (see here). As described in Slate magazine (see here), this tool predicted a 67 percent chance of at least 18 inches in New York City.
Unfortunately, most people interpreted this data that there would be 18 inches of snow, not that there could be (with a certain probability) 18 inches of snow.
It was not until Mother Nature did her experiment that we saw the outcome: not much snow in the Big Apple, more than 2 feet of snow in Boston.
The analogy with human genetics is this: it is possible to forecast the functional consequences of deleterious mutations, but it is not until the experimental snow falls – molecular or cellular experiments revealing the functional consequences of mutations – that the functional consequences are actually known. And without knowing the functional consequences of mutations, it is difficult to determine the association of these mutations with human disease.…
I was very pleased to listen to your State of the Union address and learn of your interest in Precision Medicine. As I am sure you know, this has led to a number of commentaries about what this term actually means (here, here, here). I would like to provide yet another perspective, this time from someone who has practiced clinical medicine, led academic research teams and currently works in the pharmaceutical industry.
Let me start by acknowledging that I know very little about your plan, but that is because no plan has been announced. However, that inconvenient fact should not prevent me from forming a very strong opinion about what you should do. Similar behavior is observed in politics (which you know well) and sports radio (see for example “Deflate-gate”). So here it goes…
I want to clarify my definition of “precision medicine” (see here for my previous blog on how this is different from “personalized medicine”). In the simplest of terms, precision medicine refers to the ability to classify individuals into subpopulations based on a deep understanding of disease biology. Note that this is different than what clinicians normally practice, which is to classify patients based on signs and symptoms (which can be measured by clinicians as part of routine clinical appointments).…
Welcome to our first blog of 2015 on genetics/genomics for drug discovery. After a nice vacation in sunny Arizona flying drones (here), I am back soliciting ideas from our Merck Genetic & Pharmacogenomics (GpGx) team. This week’s pick riffs off the events at J.P.Morgan 2015, where there were a number of interesting deals made by pharmaceutical companies and genetic companies (see here, here, here).
With all of this interest in human genetics, it raises the question about how genetics can be used to develop new drugs. The first step is to go from “genes to screens”. That is, the first step is to progress from a human genetic variant associated with a clinical trait of interest to an actual drug screen. This week’s article, published in Nature Chemical Biology, describes one example (see here, here).
Summary of the manuscript: Deleterious mutations in the ABHD12 gene cause a rare neuroinflammatory-neurodegenerative disorder named polyneuropathy, hearing loss, ataxia, retinitis pigmentosa and cataract (PHARC, see here). A similar phenotype is observed in ABHD12-deficient mice. ABHD12 is an enzyme degrading lysophosphatidylserine (lyso-PS), a signaling lipid known to regulate macrophage activation. The Nature Chemical Biology study by Kamat and colleagues describes the chemical proteomic identification of a related enzyme, ABHD16A, which synthesizes the terminal step leading to lyso-PS generation.…
I got a drone for Christmas. The first thing my wife asked me was, “Why do you need a drone?” I did not have a great answer, other than to say it would be fun to take aerial videos. My sister teased me, as did my kids, nieces and nephew (Sam Sutherland). They said I was obsessed; they said I was acting like a little kid. My neighbors were worried – “no more nude sunbathing” was awkwardly expressed by more than one.
The new recreational drones represent pretty cool technology. Just a few years ago, the technology was not available to stabilize and control the flying of drones…at least not at an affordable cost. Now, GPS satellites and gyro sensors can do just that. Until recently, the range on remote controlled drones was relatively limited. Now, wireless communication allows for first-person viewing and long-distance control at long-range (up to 500 meters from my Phantom DJI FC40 drone). And until recently, the cameras attached to drones were not of sufficient quality to record high-definition images. Now, simple microchips installed in HD cameras with stabilizing functions allow for professional-grade photography (e.g., GoPro).
And with these drones, there is a new perspective on old things.…
This week’s theme is genes to function for drug screens…with a macabre theme of zombies! As more genes are discovered through GWAS and large-scale sequencing in humans, there is a pressing need to understand function. There are at least two steps: (1) fine-mapping the most likely causal genes and causal variants; and (2) functional interrogation of causal genes and causal variants to move towards a better understanding of causal human biology for drug screens (“from genes to screens”).
Genome-editing represents one very powerful tool, and the latest article from the laboratory of Feng Zhang at the Broad Institute takes genome-editing to a new level (see Genetic Engineering & Biotechnology News commentary here). They engineer the dead!
Since its introduction in late 2012, the CRISPR-Cas9 gene-editing technology has revolutionized the ways scientists can apply to interrogate gene functions. Using a catalytically inactive Cas9 protein (dead Cas9, dCas9) tethered to an engineered single-guide RNA (sgRNA) molecule, the authors demonstrated the ability to conduct robust gain-of-function genetic screens through programmable, targeted gene activation.
Earlier this year, the laboratories of Stanley Qi, Jonathan Weissman and others \ reported the use of dCas9 conjugated with a transcriptional activator for gene activation (see Cell paper here).…
Welcome to this second blog post on genetics/genomics for drug discovery! So far, we are 2 for 2. That is, this is the second week in a row where we have reviewed the literature for interesting journal articles and written a blog on why the study is relevant for drug discovery. I say “we”, because this week I asked for input from our Merck Genetic & Pharmacogenomics (GpGx) team. We received a number of interesting submissions from GpGx team members, as summarized at the end of the blog.
This week’s article uses antisense as therapeutic proof-of-concept in humans for a genetic target…again! This story is reminiscent of last week’s post on APOC3 (see here).
Summary of the manuscript: While patients with congenital Factor XI deficiency have a reduced risk of venous thromboembolism (VTE), it is unknown whether therapeutic modulation of Factor XI will prevent venous thromboembolism without increasing the risk of bleeding. In this open-label, parallel-group study, 300 patients who were undergoing elective primary unilateral total knee arthroplasty were randomly assigned to receive one of two doses of FXI-ASO (200 mg or 300 mg) or 40 mg of enoxaparin once daily.…
There are an increasing number of very interesting published studies around genetics / genomics and drug discovery. Just last week, there were a series of articles in Nature on predictors of response to anti-PD1 therapy. (Disclaimer: I work for Merck, which markets an anti-PD1 drug.) In this new blog series, I try and pick at least one paper that highlights some of the key principles of genetics/genomics and drug discovery. This is week #1…hopefully I will be able to do this routinely!
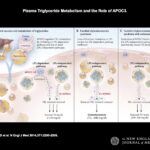
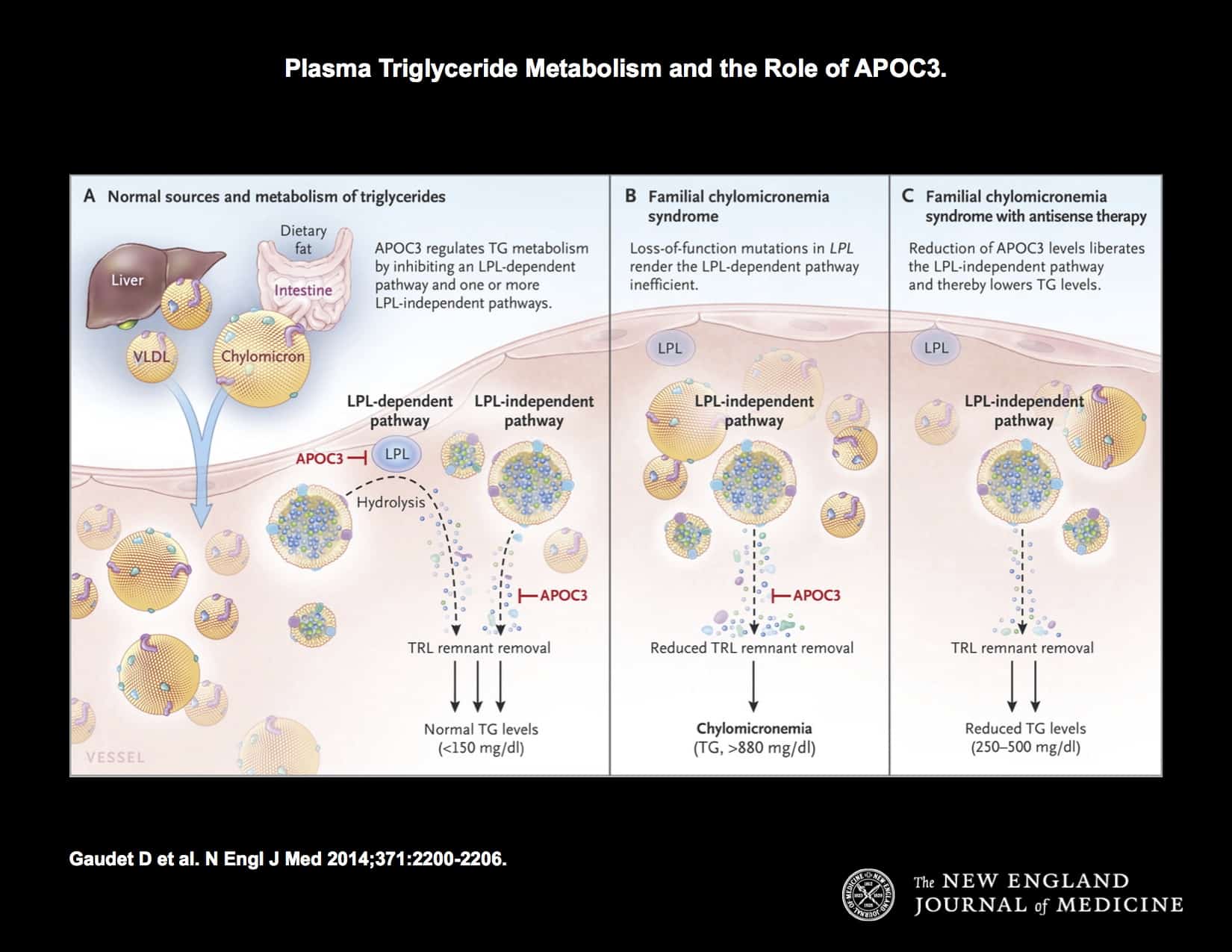
This week, I have selected an article in NEJM by Gaudet et al: Targeting APOC3 in the Familial Chylomicronemia Syndrome. As described in the introduction: “The familial chylomicronemia syndrome is a rare autosomal recessive disease characterized by the buildup in the blood of fat particles called chylomicrons (chylomicronemia), severe hypertriglyceridemia, and the caused by mutations in the gene encoding LPL or, less frequently, by mutations in genes encoding other proteins necessary for LPL function. Patients with this syndrome have plasma triglyceride levels ranging from 10 to 100 times the normal value (1500 to 15,000 mg per deciliter [17 to 170 mmol per liter]), eruptive xanthomas, arthralgias, neurologic symptoms, lipemia retinalis, and hepatosplenomega without pancreatitis, that interfere with normal life and result in frequent hospitalizations.”…
At the Harvard-Partners Personalized Medicine Conference last week I participated in a panel discussion on complex traits. When asked about where personalized medicine for complex traits will be in the future, I answered that I envision two major categories for personalized therapies.
(1)Development of drugs based on genetic targets will lead to personalized medicine; and
(2)Large effect size variants will be detected in clinical trials or in post-approval studies and will lead to personalized medicine.
This answer, I said, was based in part on current categories of FDA pharmacogenetic labels and in part on how I see new drug discovery occurring in the future. But did the current FDA labels really support this view?
The answer is “yes”. In reviewing the 158 FDA labels (Excel spreadsheet here), my crude analysis found that 31% of labels fall into the “genetic target” category (most from oncology – 26% of total) and 65% fall into the “large effect” category (most from drug metabolism [42% of total], HLA or G6PD [15% of total]).
A subtle but important point is that I predict that category #2 (PGx markers for non-oncology “genetic targets”) will grow in the future. In other words, development of non-oncology drugs will riff-off the success of drugs developed based on somatic cell genetics in oncology. …
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}