
In this post I will build on previous blogs (here, here, here) about genetics for target ID and validation (TIDVAL). Here, I argue that new targets with unambiguous promotable advantage will emerge from studies that focus on genetic pathways rather than single genes.
This is not meant to contradict my previous post about the importance of genetic studies of single genes to identify new targets. However, there are important assumptions about the single gene “allelic series” approach that remain unknown, which ultimately may limit its application. In particular, how many genes exist in the human genome have a series of disease-associated alleles? There are enough examples today to keep biopharma busy. Moreover, I am quite confident that with deep sequencing in extremely large sample sizes (>100,000 patients) such genes will be discovered (see PNAS article by Eric Lander here). Given the explosion of efforts such as Genomics England, Sequencing Initiative Suomi (SISu) in Finland, Geisinger Health Systems, and Accelerating Medicines Partnership, I am sure that more detailed genotype-phenotype maps will be generated in the near future.
[Note: Sisu is a Finnish word meaning determination, bravery, and resilience; it is about taking action against the odds and displaying courage and resoluteness in the face of adversity. As such, it seems apropos to efforts in genetics and drug discovery!]
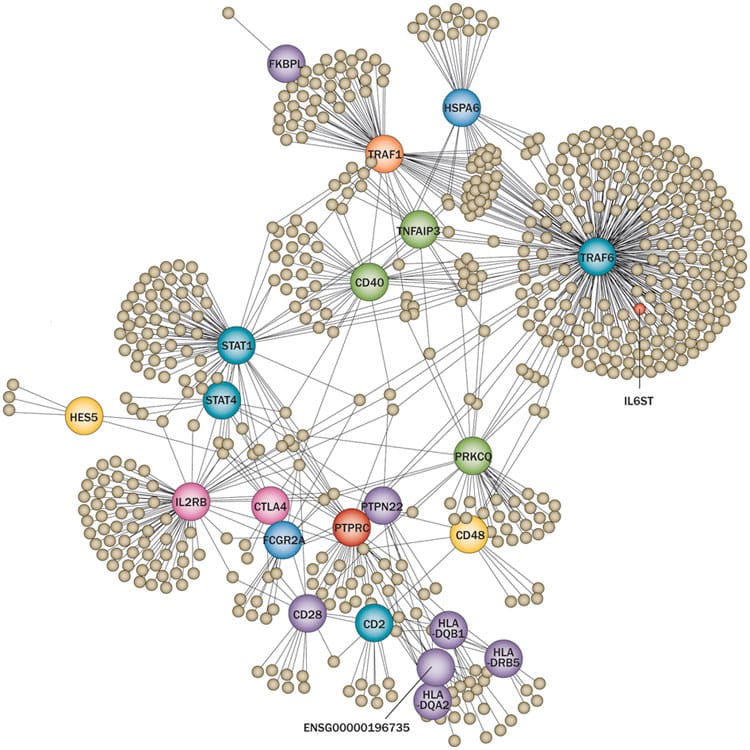
But a complementary approach is to model alleles associated with complex traits from GWAS or related approaches to define critical pathways. The foundation for this approach comes from the observation that complex traits such as risk of disease or response to therapy are highly polygenic (see here and here). That is, hundreds (if not thousands) of alleles at independent loci each have a subtle effect, which in aggregate influence complex traits.
I propose six steps to link genetics to pathways for drug discovery:
(1) Establish a relationship between clinical phenotype, human genetics and drug efficacy. As I have discussed previously, it is important to choose phenotypes that are appropriate surrogates for drug efficacy (see here).
(2) Identify alleles that are associated with phenotype of interest. GWAS is a powerful ally to find alleles that are associated with a human phenotype of interest. However, genetic studies of rare families segregating a highly penetrant phenotype in a Mendelian fashion are also quite powerful. In fact, the two strategies often complement each other, as is the case for the relationship between rare Mendelian forms of primary human immunodeficiency and genes implicated in RA and other autoimmune diseases. As one example, rare human mutations that completely knock-out the JAK3 gene cause primary immunodeficiency. The JAK-STAT-IL6 pathway is implicated in GWAS of RA (see here). The FDA recently approved a pan-JAK inhibitor, tofacitinib, for the treatment of RA. We also quantitatively demonstrated the relationship between genetics of RA and approved drugs for RA in our 2014 Nature paper (see here).
(3) Integrate human genetic data with ‘omics and biological data to uncover relevant pathways. A wide-variety of inputs has been used – gene expression, epigenetic data, protein-protein interactions, annotated pathways…even free-text from PubMed abstracts (see full-text manuscripts here, here and here). Model organisms are also very important in deriving insights into fundamental biological pathways (for example, see Immunological Genome Project, or ImmGen).
The resolution of the underlying biology is dependent on the resolution of the data. For example, PubMed text provides a rich source of data to establish connection, but the biological interpretations that emerge from relationships across loci is somewhat limited. In contrast, cell-specific gene expression and epigenetic data (see here) are useful, but the power is dependent on the number of distinct cell types with available genome-wide data.
(4) Test the pathway in relevant tissue from patients with disease. While a correlation between GWAS hits and a biological pathway strongly implicates the pathway in disease, the connection is not perfect. In particular, it may not be obvious from genetic data alone whether the pathway is up- or down-regulated in disease states. To establish this relationship, it is necessary to test the biological pathway in the relevant tissue type in patients with disease, compared to those without the disease.
(5) Identify key nodes of the biological pathway. Once the pathway is identified, it is important to identify key nodes that can serve as the target of therapeutic modulation. To identify key nodes of pathways, animal models and other experimental data are required. These experiments might be hypothesis-driven, especially if there is a detailed understanding of the biochemical pathway (e.g., HMG CoA reductase in cholesterol biosynthesis – which led to the development of statins). If little is known about the pathway, then an unbiased approach is to use the pathway as a molecular readout, and then to perform systematic perturbation of the pathway using RNAi. Another strategy is to use phenotypic screens (see below).
(6) Develop drugs that target key nodes of the pathway. Once the nodes have been identified, drugs are developed that target those nodes. (Of course, this is easier said than done!)
An example of this approach in action is from a recent paper in Nature Medicine, which followed up on a GWAS for alopecia; this led to repurposing of a JAK-inhibitor (see here, here).
Before concluding, I want to briefly highlight the role of phenotypic screens, which serve as an alternative to steps #5 and #6 above. Recent data suggest that phenotypic screens are more likely to result in drugs with a novel mechanism of action (see here, here and here). An explanation for this observation is that phenotypic screens attempt to model the biological complexity that is the basis of most common diseases. Phenotypic screens don’t assume that a single target perturbed in a very specific manner will lead to a safe and effective drug. Moreover, phenotypic screens allow for the possibility that a small molecule will perturb more than one target, or that target modulation will occur in a way that cannot be easily recapitulated in a simple biochemical assay.
I think that human genetics is an innovative approach to develop assays for phenotypic screens. One example is a study my former academic lab published in PLoS Genetics (see here).
This post concludes the four-part series on genetics for drug discovery. I have received many useful comments on my Twitter account (@rplenge) [e.g., important role of model organisms; complementary data from epigenetics; hype of genome sciences – “haven’t we said we are at an inflection point before?”]. I hope that my blog posts continue the important conversation, as these are all ideas in progress. By way of review:
Part 1: The case for genetics in TIDVAL – the key is to find targets with novel MOA and an increased probability of success to differentiate in the clinic
Part 2: Phenotype matters – not all phenotypes are relevant for genetics and drug discovery…but which ones are?
Part 3: One gene, one target, one drug – human genetics can find genes with an allelic series to estimate dose-response curves at the time of target ID and validation
Part 4: Many genes to pathways to targets – a systems biology approach, anchored in human genetic, is a powerful complement to the one gene “allelic series” TIDVAL approach