When I last wrote about AI on this blog three years ago, I spoke of it being a tool with the potential to transform scientific discovery, but the application I described was primarily theoretical. For AI to be a meaningful tool in R&D, I argued, we needed better sources of “truth” – better data sets that AI tools could query and learn from over time – and technology capable of integrating multiple steps into a semi-automated system. My message was that AI-enabled drug discovery was coming…someday.
Fast forward to 2025, and that someday is now.
We’ve seen an explosion in the availability and capability of AI tools. Just 10 months after I wrote about the theoretical possibilities of AI in biopharma, OpenAI debuted ChatGPT. Shortly after that, we saw the rollout of Microsoft Copilot and Meta AI. We now have immense computational power at our fingertips, with programs specifically designed to query biological problems. Combined with the ingenuity of skilled scientists, who can define the research problem and generate curated datasets that will enable solutions, AI has become an important and practical tool that is helping researchers accelerate discovery (link to Google DeepMind podcast on this topic here; link to a start-up’s pragmatic journey of AI in drug discovery here).…
Disclaimer: I am a full-time employee of Bristol Myers Squibb.
When I practiced clinical rheumatology, I would often see patients with autoimmune conditions like systemic lupus erythematosus (SLE), systemic sclerosis (scleroderma), rheumatoid arthritis (RA), or myositis. A typical patient journey included an initial sense of relief when a diagnosis was established and a medicine was started. Inevitably, however, there was a sense of dread when a patient would ask: “When am I able to stop taking these strong immunosuppressive medicines?”
I would answer: “Likely never.”
That’s because, historically, there have been no cures for these diseases.
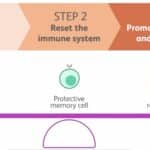
Now, however, I believe there may be an opportunity for new strategies that may deliver transformational outcomes for patients. In a new review paper published in Nature Reviews Drug Discovery (NRDD) (link here), our team at Bristol Myers Squibb (BMS), led by Dr. Francisco Ramírez-Valle, describes a “sequential immunotherapy” strategy that has the goal of achieving durable remissions and even functional cures. I presented an example of this strategy in action for SLE at the Stanford Drug Discovery Symposium. I also discussed the potential for functional cures during a recent BioCentury Show podcast and as part of NRDD’s “An Audience With” series.…
[ I am an employee of Bristol Myers Squibb. The views expressed here are my own, assuming I am real and not a humanoid. ]
In the original Blade Runner (1982), Harrison Ford’s character, Deckard, implements a fictitious Voight-Kampff test to measure bodily functions such as heart rate and pupillary dilation in response to emotionally provocative questions. The purpose: to establish “truth”, i.e., determine whether an individual is a human or a bioengineered humanoid known as a replicant.
While the Voight-Kampff test was used to establish truth for humans vs replicants, the concept of “truth” is central to neural networks used in machine learning and artificial intelligence (AI). And for AI to be effective in drug discovery and development, it is critical to ask a fundamental question: what is “truth” in drug discovery and development?
INTRODUCTION
I recently read the book Genius Makers by Cade Metz and was reminded of the long history of machine learning, neural networks, and artificial intelligence (AI). This is a field more than 60 years in the making, with slow growth for the first 50 years – AI was founded as an academic discipline in 1956 – and exponential growth in the last 10. The original mathematical framework of neural networks was created in the 50’s (perceptron), 60’s and 70’s (backpropagation), but went largely unappreciated outside of academics, as the practical applications were few and far between.…
[Disclaimer: I am an employee of Celgene. The views reported here are my own.]
I presented at the PharmacoGenomics Research Network (PGRN) portion of the 2018 ASHG meeting (link to my slides here). A major theme from my talk was that precision medicine holds promise for advancing novel therapies, but that implementation of pharmacogenomics (PGx) will happen by design not by accident. Here is what I mean – and why our health care systems need to build for this future state today.
PGx by design – PGx by design starts at the very beginning of the drug discovery journey, when the choice is made to develop a therapeutic molecule against a target or a pathway. A precision medicine hypothesis is carried forward into the design of a therapeutic molecule (“matching modality with mechanism”), pre-clinical biomarkers to measure pharmacodynamic responses, and early proof-of-concept clinical studies in defined patient subsets. Late-stage clinical development is performed in these patient subsets, and regulatory approval is obtained with a label that defines this patient subset. Health care systems will essentially be required to incorporate precision medicine into patient care.
There are emerging examples of PGx by design. Indeed, there are an increasing number of FDA approvals that fit with the PGx by design model (see figure below).…
[I am an employee of Celgene. All views expressed here are my own.]
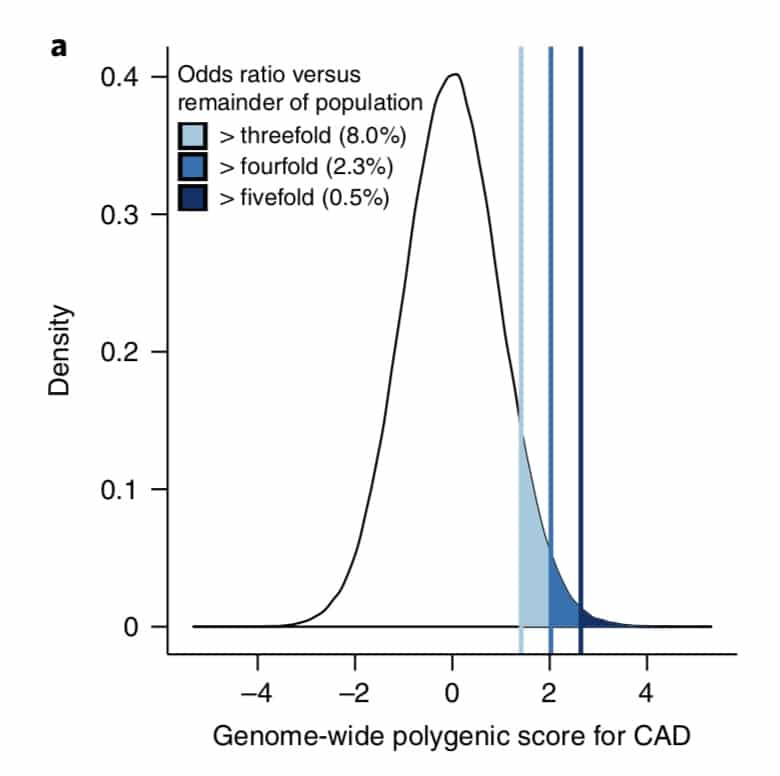
What is the clinical significance of residing within the tail of a distribution for disease risk? A new study published in Nature Genetics uses a composite polygenic score to measure extremes of genetic risk(see original article here). The authors make the bold statement: “it is time to contemplate the inclusion of polygenic risk prediction in clinical care”. In this plengegen.com blog, I briefly review the paper, frame the impact of the study in terms of “long tails”, and propose how genetic tails may be used as part of a healthcare system reimagined.
The premise of the paper is that a genome-wide polygenic score (GPS) – a composite genetic test that includes thousands and sometimes millions of genetic variants – can identify a small number of individuals from the general population that have an elevated risk. The study applies polygenic risk scores to five common diseases but spends most attention to coronary artery disease (CAD). For each disease, the increase in risk is approximately 3- to 5-fold higher among individuals at the extreme of the polygenic tail compared to those in the general population – see Figure 2a (and below) for CAD, where ~8% of the general population is at a 3-fold increase in risk based on a polygenic risk score.…
A new genetics initiative was announced today: the creation of FinnGen (press release here). FinnGen’s goal is to generate sequence and GWAS data on up to 500,000 individuals with linked clinical data and consented for recall. There are many applications for such a resource, including drug discovery and development. In this blog, I want to first describe the application of PheWAS for drug discovery and development, and then introduce FinnGen as a new PheWAS resource (see FinnGen slide deck here).
[Disclaimer: I am an employee of Celgene. The views expressed here are my own.]
PheWAS
PheWAS turns GWAS on its head. While GWAS tests millions of genetic variants for association to a single trait, PheWAS does the opposite: tests hundreds (if not thousands) of traits for association with a single genetic variant. This approach is primarily relevant for those genetic variants with an unambiguous functional consequence – for example, a variant associated with disease risk or a variant that completely abrogates gene function. There are useful online resources (see here), as well as several nice recent reviews by Josh Denny and colleagues, which provide additional background on PheWAS (see here, here).
Work that originated from my academic lab represents the first example of PheWAS for drug discovery – in particular, how to use PheWAS to predict on-target adverse drug events (ADEs) and to select indications for clinical trials (see 2015 PLoS One publication here).…
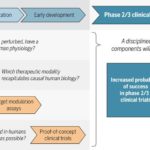
As readers of my blog know, I am a strong supporter of a disciplined R&D model that focuses on: picking targets based on causal human biology (e.g., genetics); developing molecules that therapeutically recapitulate causal human biology; deploying pharmacodynamic biomarkers that also recapitulate causal human biology; and conducting small clinical proof-of-concept studies to quickly test therapeutic hypotheses (see Figure below).As such, I am constantly on the look-out for literature or news reports to support / refute this model.Each week, I cryptically tweet these reports, and occasionally – like this week – I have the time and energy to write-up the reports in a coherent framework.
Of course, this model is not so easy to follow in the real-world as has been pointed out nicely by Derek Lowe and others (see here).A nice blog this week by Keith Robison (Warp Drive Bio) highlights why drug R&D is so hard.
Here are the studies or news reports from this week that support this model.
(1) Picking targets based on causal human biology: I am a proponent of an “allelic series” model for target identification. Here are a couple of published reports that fit with this model.…
Like many, I waited with bated breath for results of the anti-PCSK9 (evolocumab) FOURIER cardiovascular outcome study last week. There have been many interesting commentaries written on the findings.A few of my favorites are listed here (Matthew Herper), here (David Grainger), here (Derek Lowe), and here (Larry Husten), amongst others, with summaries provided at the end of this blog.Most of these articles focused on clinical risk reduction vs. what was predicted for cardiovascular outcome, as well as whether payers will cover the cost of the drugs.These are incredibly important topics, and I won’t comment on them further here, other than to say that the debate is now about who should get the drug and how much it should cost.
In this blog, I want to emphasize key points that pertain to human genetics and drug discovery.And make no mistake: the anti-PCSK9 story and FOURIER clinical trial outcome is a triumph for genetics and drug discovery. This message seems to be getting muddled, however, given the current cost of evolocumab and the observation that cardiovascular risk reduction was less than expected, based on predictions from a 2005 study published by Cholesterol Treatment Trialists (CTT) (see Lancet study here).…
Yesterday I participated in the National Academy workshop, “Enabling Precision Medicine: The Role of Genetics in Clinical Drug Development” (link here). There were a number of great talks from leaders across academics, industry and government (agenda here).
I was struck, however, by a consistent theme: most think that “precision medicine” will improve delivery of approved therapies or those that are currently being developed, whether or not the therapies were developed originally with precision medicine explicitly in mind. Many assume that the observation that ~90% medicines are effective in only 30% to 50% is the result of biological differences in people across populations (see recent Forbes blog here). This hypothesis is very appealing, as there are many unique features to each of us.
An alternative explanation is that most medicines developed without precision medicine from the beginning only work in ~30% patients because the medicines don’t target the biological pathways that make each of us unique.
I believe the most likely application is in the discovery and development of new therapies. That is, I believe that the greatest impact will come when precision medicine strategies are incorporated into the very beginning of drug discovery, and will only rarely have an impact on therapies that were not developed with precision medicine in mind from the start.…
A new sickle cell anemia gene therapy study published in the New England Journal of Medicine (see here, here) gives hope to patients and the concept of rapidly programmable therapeutics based on causal human biology. But how close are we really?
It takes approximately 5-7 years to advance from a therapeutic hypothesis to an early stage clinical trial, and an additional 4-7 years of late stage clinical studies to advance to regulatory approval. This is simply too long, too inefficient and too expensive.
But how can timelines be shortened?
In the current regulatory environment, it is difficult to compress late stage development timelines. This leaves the time between target selection (or “discovery”) and early clinical trials (ideally clinical proof-of-concept, or “PoC”) as an important time to gain efficiencies. Further, discovery to PoC is an important juncture for minimizing failure rates in late development and delivering value to patients in the real world (see here).
Here, I argue that rapidly programmable therapeutics based a molecular understanding of the causal disease process is key to compressing the discovery to PoC timeline.
Imagine a world where the molecular basis of disease is completely understood. For common diseases, germline genetics contributes approximately two-thirds of risk; for rare diseases, germline genetics contributes nearly 100% of risk.…
“Water does not resist. Water flows…But water always goes where it wants to go, and nothing in the end can stand against it.” – Margaret Atwood
“The path of least resistance leads to crooked rivers and crooked men.” – Henry David Thoreau
What fraction of potential protein targets is accessible to conventional therapeutic modalities such as small molecules and protein biologics? The “druggable genome”, a term coined by Hopkins and Groom in 2002 (here), provides an estimate: approximately 10% of proteins in the human body are druggable by small molecule therapeutics. Greg Verdine and others estimate that an additional 10% of protein targets – those that are extracellular proteins – are druggable by biologics (here; excellent podcast by Janelle Anderson, humanPoC, here). Derek Lowe, however, has blogged that there is a lot of uncertainty in these estimates (here, here).
These two issues create a natural tension for drug hunters at the start of a drug discovery program: pursue those targets that are druggable or those targets with the most compelling human evidence.…
It has been a good week for human genetics, with high-profile studies published in Science (here) and NEJM (here, here, here), and a summit at the White House on Precision Medicine. Here, I summarize the published studies and put them in context for drug discovery. But first, I want to briefly detour into a story about the Wright Brothers.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
In 1900, Wilbur and Orville Wright first began experiments with their flying machine. They defined three problems for manned flight: power, wing structure and control. As described beautifully in David McCullough’s book (review here), the brothers focused on the latter, control, which when sufficiently solved led to the first manned flight in 1903. Within ten years of solving the “flying problem”, aviation technology progressed to the point that manned flights were routine.
By analogy, I would argue that there are three key challenges for drug discovery: targets, biomarkers and clinical proof-of-concept studies. The key problem to solve is target selection. Today, we do not know enough about causal human biology to select targets, and as a consequence we have a crisis in cost (drugs are too expensive to develop because of failures at the most costly stage, late development) and innovation (for those drugs that work, there is insufficient differentiation from standard-of-care treatments to change health care outcomes).…
A study published last week in Science described a large-scale genetic association study of Neandertal-derived alleles with clinical phenotypes from electronic health records (EHRs). Here, I focus less on the Neandertal aspect of the study – which to me is really just a gimmick and not medically relevant – and more on the ability to use EHR data for unbiased association studies against a large number of clinical traits captured in real-world datasets. I also provide some thoughts on how this same approach could be used for drug discovery.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
The study used clinical data from the Electronic Medical Records and Genomics (eMERGE) Network, a consortium that unites EHR systems linked to patient genetic data from nine sites across the United States. The clinical data was primarily from ICD9 billing codes, an imperfect but decent way to capture clinical data from EHRs. In total, a set of 28,416 adults of European ancestry from across the eMERGE sites had both genotype data and sufficient EHR data to define clinical phenotypes (n=13,686 in the Discovery set; n=14,730 in the replication set).…
This week I want to focus on the role of biomarkers in drug discovery and development, which is one of the three pillars of a successful translational medicine program (see slide deck here). The focus is on Alzheimer’s disease, based on recent articles published in JAMA. At the end of the blog you will find postings for new biomarker positions in Merck’s Translational Medicine Department.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
Before I start, I want to point to a few blogs that provide counterarguments to some of the optimistic opinions expressed in this blog. The first is David Dobb’s negative view on big data (here); the second on Larry Husten’s concerns about conflicts of interest between academics and industry, as it relates to a recent NEJM series (here). I will not comment further, but it is worth pointing readers to these blogs and related blogs for a balanced view on complicated topics.
I have expressed the strong opinion that what ails drug discovery and development is that we pick the wrong targets, don’t develop robust biomarkers, and we don’t test therapeutic hypotheses quickly enough in clinical trials.…
The primary purpose of this blog is to recruit clinical scientists into our new Translational Medicine department at Merck (job postings at the end). However, I hope that the content goes beyond a marketing trick and provides substance as to why translational medicine is crucial in drug discovery and development. Moreover, I have embedded recent examples of translational medicine in action, so read on!
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
There is a strong need to recruit clinical scientists into an ecosystem to develop innovative therapies that make a genuine difference in patients. This ecosystem requires those willing to toil away at fundamental biological problems; those committed to converting biological observations into testable therapeutic hypotheses in humans; and those who develop therapies and gain approval from regulatory agencies throughout the world. The first step is largely done in academic settings, and the other two steps largely done in the biopharmaceutical industry…although I am sure there are many who would disagree with this gross generalization!
The term “Translational Medicine” has been broadly used to describe the second step, thereby bridging the Valley of Death between the first and third steps.…
Many of you are probably fully aware of how immuno-oncology is changing cancer treatment. Ken Burns highlighted immunotherapy in his recent PBS series, “Cancer: The Emperor of All Maladies” (video link here). Forbes’ Matthew Herper, BBC and others have written extensively about it, too (here, here). More recently, Genome Magazine had a feature article on the history of immunotherapy (here). As the article states: “The promise of immunotherapy is startling in its simplicity: With a little help from cancer doctors, the patients will cure themselves.”
The key word here is “cure”. Cure!
The purpose of this blog is two-fold: (1) introduce geneticists and genomicists to cancer immunotherapy, if they have not thought about it before, and (2) highlight a recent Science publication by Elaine Mardis, Gerald Linette, and colleagues at WashU (here), with an accompanying News & Views article in Nature (here).
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
Cancer immunotherapy is really cool! As a former practicing rheumatologist at Brigham and Women’s Hospital, I had thought about the role of neoantigens in autoimmunity for many years.…
I admit upfront that this is a self-serving blog, as it promotes a manuscript for which I was directly involved. But I do think it represents a very nice example of the role of human genetics for drug discovery. The concept, which I have discussed before (including my last blog), is that there is a four-step process for progressing from a human genetic discovery to a new target for a drug screen. A slide deck describing these steps and applying them to the findings from the PLoS One manuscript can be found here, which I hope is valuable for those interested in the topic of genetics and drug discovery.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer. However, the PLoS One study was performed while I was still in academics at BWH/Harvard/Broad.]
Before I provide a summary of the study, I would like to highlight a few recent news stories that highlight that the world thinks this type of information is valuable. First, the state of California is investing US $3-million in a precision medicine project that links genetics and medical records to develop new therapies and diagnostics (here, here).…
There was an eruption in Iceland last week. No, this was not another volcanic eruption. Rather, there was a seismic release of human genetic data that provides a glimpse into the future of drug discovery. The studies were published in Nature Genetics (the issue’s Table of Contents can be found here), with insightful commentary from Carl Zimmer / New York Times (here), Matthew Herper / Forbes (here), and others (here, here).
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
As I have commented before, human genetics represent a very powerful approach to identify new drug targets (see here, here). I have articulated a 4-step process (see slide #5 from this deck): (1) select a phenotype that is relevant for drug discovery; (2) identify a series of genetic variants (or “alleles”) that is associated with the phenotype; (3) assess the biological function of phenotype-associated alleles; and (4) determine if those same alleles are associated with other phenotypes that may be considered adverse drug events.
There is an important assumption about this model: genes with an “allelic series” will be identified from large-scale genetic studies, and these phenotype-associated alleles will serve as an estimate of function-phenotype dose-response curves.…
My overly simplistic vision of the way to transform drug discovery is to (1) pick targets based on causal human biology (e.g., experiments of nature, especially human genetics), (2) develop drugs that recapitulate the biology of the human experiments of nature (e.g., therapeutic inhibitors of proteins), (3) develop biomarkers that measure target modulation in humans, and (4) test therapeutic hypotheses in humans as safely and efficiently as possible.
Thus, one of my favorite themes is “causal human biology”. The word “causal” is key: it means that there is clear evidence between the cause-effect relationship of target perturbation in humans and a desired effect on human physiology. Human genetics represent one way to get at causal human biology, and in my last blog I highlighted recent examples outside of human genetics.
I am constantly scanning the literature to find examples that support or refute this model, as I predict that a discipline portfolio of projects based on causal human biology will be more successful than past efforts by the pharmaceutical industry.
This week I have selected two articles on genetics/genomics in drug discovery that provide further support of this model. [Disclaimer: the first study was funded by Merck, my employer.]…
I was very pleased to listen to your State of the Union address and learn of your interest in Precision Medicine. As I am sure you know, this has led to a number of commentaries about what this term actually means (here, here, here). I would like to provide yet another perspective, this time from someone who has practiced clinical medicine, led academic research teams and currently works in the pharmaceutical industry.
Let me start by acknowledging that I know very little about your plan, but that is because no plan has been announced. However, that inconvenient fact should not prevent me from forming a very strong opinion about what you should do. Similar behavior is observed in politics (which you know well) and sports radio (see for example “Deflate-gate”). So here it goes…
I want to clarify my definition of “precision medicine” (see here for my previous blog on how this is different from “personalized medicine”). In the simplest of terms, precision medicine refers to the ability to classify individuals into subpopulations based on a deep understanding of disease biology. Note that this is different than what clinicians normally practice, which is to classify patients based on signs and symptoms (which can be measured by clinicians as part of routine clinical appointments).…














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}