[ I am an employee of Bristol Myers Squibb. The views expressed here are my own, assuming I am real and not a humanoid. ]
In the original Blade Runner (1982), Harrison Ford’s character, Deckard, implements a fictitious Voight-Kampff test to measure bodily functions such as heart rate and pupillary dilation in response to emotionally provocative questions. The purpose: to establish “truth”, i.e., determine whether an individual is a human or a bioengineered humanoid known as a replicant.
While the Voight-Kampff test was used to establish truth for humans vs replicants, the concept of “truth” is central to neural networks used in machine learning and artificial intelligence (AI). And for AI to be effective in drug discovery and development, it is critical to ask a fundamental question: what is “truth” in drug discovery and development?
INTRODUCTION
I recently read the book Genius Makers by Cade Metz and was reminded of the long history of machine learning, neural networks, and artificial intelligence (AI). This is a field more than 60 years in the making, with slow growth for the first 50 years – AI was founded as an academic discipline in 1956 – and exponential growth in the last 10. The original mathematical framework of neural networks was created in the 50’s (perceptron), 60’s and 70’s (backpropagation), but went largely unappreciated outside of academics, as the practical applications were few and far between.…
[I am an employee of Bristol-Myers Squibb. The views expressed here are my own.]
One of my predictions for the next decade – the “clear view” decade – is that we will have the ability to click on any gene in the human genome to generate function-phenotype maps. These maps should enable drug discovery by informing on mechanism, magnitude and markers of target perturbation. In particular, I have championed an “allelic series” model, whereby genes with a series of alleles are used to derived genetic dose-response curves (see here, here).
During a recent presentation to my former colleagues at the Division of Genetics at Brigham & Women’s Hospital (BHW, slides here), I discussed important assumptions underlying this model:
Large-scale sequence data will identify a range of protein-coding variants associated with traits of medical interest that are suitable surrogates for drug discovery (allelic series architecture assumption).
It will be possible to use high-throughput functional assays to interrogate the impact of trait-associated variants on cell physiology for the majority of genes in the genome (functional readout assumption).
Large-scale biobanks will emerge to enable testing of these same trait-associated variants for pleiotropic effects across a wide-variety of clinical phenotypes in the real world (PheWAS assumption).
[I am an employee of Celgene. The views expressed here are my own.]
In the Wizard of Oz, Dorothy clicks her heels and hopes for re-entry from her dream world by repeating, “There’s no place like home…there’s no place like home…” I often feel that many in the genetics community look at their human genetics data with the same youthful optimism as Dorothy – clicking their genetic heels and wishing “my genetic discovery will become a drug…my genetic discovery will become a drug…” But without rigor and discipline, such heel-clicking won’t overcome many of the challenges that face drug hunters along the tortuous journey from a genetic idea to a new medicine.
In this blog, I discuss a recent study on the genetics of multiple sclerosis (MS) published in Science (see here). This is a beautiful study that substantially advances the genetic landscape of patients with a devastating disease. However, the study falls short in terms of the application of human genetics to drug discovery. To chart a course for the future, I introduce the concept of mechanism, magnitude and markers (oh my!), which I refer to as the three M’s. …
[I am an employee of Celgene. All views expressed here are my own.]
At the 2018 Annual Atlas Ventures Retreat (AVR), I participated in a panel on Digital Health (along with David Schenkhein, John Reed, Scott Brun). The panel discussion was led by Michael Ringel, who also provide an excellent introduction to Digital Health (his slides here). While there are many aspects to digital health, we focused on the application to drug discovery and development. In this blog, the main point I want to emphasize is that I believe that the digital health tipping point will occur when products that benefit patients (e.g., therapeutics) facilitate the integration of digital health initiatives that currently reside in silos.
What is digital health in relation to drug discovery & development? There are many different definitions with many different components, and this, in essence, is part of the challenge (see Figure below). In early discovery biology, digital health represents various data types (e.g., human genetics, ‘omics data, cell models) and analytical methods (e.g., simple regression, machine learning, artificial intelligence). In late discovery biology, digital health includes sophisticated analytical methods for in silico drug design and organoid models to recapitulate the human system for pre-clinical testing.…
[I am an employee of Celgene. All opinions expressed here are my own.]
A meeting was recently convened to discuss a roadmap for understanding the genetics of common diseases (search Twitter for #cdcoxf18). I presented my vision of a genetics dose-response portal (slides here; link to related 2018 ASHG talk here). The organizers (@RachelGLiao, @markmccarthyoxf, @ceclindgren, Rory Collins [Oxford], Judy Cho [New York], @NancyGenetics, @dalygene, @eric_lander) asked participants to share their vision. I thought I would blog about my mine.
You’ll notice my vision is ambitious. Nonetheless, I believe these objectives are feasible to accomplish within a 3-year (Phase 1) and 7-year (Phase 2) time frame. Phase 1 would start immediately and would guide projects for Phase 2. In reality, many aspects of Phase 1 are already underway today (e.g., GWAS catalogue at EBI; Global Alliance for Genomics and Health [GA4GH] data sharing methods). Phase 2 consists of two parts: federation of global biobanks and experimental validation of variants, genes and pathways. Some components of Phase 2 could start today (e.g., exome sequencing in >100,000 cases selected from existing case-control cohorts and biobanks; human knockout project). As with Phase 1, many components of Phase 2 are already underway (federation of existing biobanks [e.g.,…
[Disclaimer: I am an employee of Celgene. The views reported here are my own.]
I presented at the PharmacoGenomics Research Network (PGRN) portion of the 2018 ASHG meeting (link to my slides here). A major theme from my talk was that precision medicine holds promise for advancing novel therapies, but that implementation of pharmacogenomics (PGx) will happen by design not by accident. Here is what I mean – and why our health care systems need to build for this future state today.
PGx by design – PGx by design starts at the very beginning of the drug discovery journey, when the choice is made to develop a therapeutic molecule against a target or a pathway. A precision medicine hypothesis is carried forward into the design of a therapeutic molecule (“matching modality with mechanism”), pre-clinical biomarkers to measure pharmacodynamic responses, and early proof-of-concept clinical studies in defined patient subsets. Late-stage clinical development is performed in these patient subsets, and regulatory approval is obtained with a label that defines this patient subset. Health care systems will essentially be required to incorporate precision medicine into patient care.
There are emerging examples of PGx by design. Indeed, there are an increasing number of FDA approvals that fit with the PGx by design model (see figure below).…
[I am an employee of Celgene. All views expressed here are my own.]
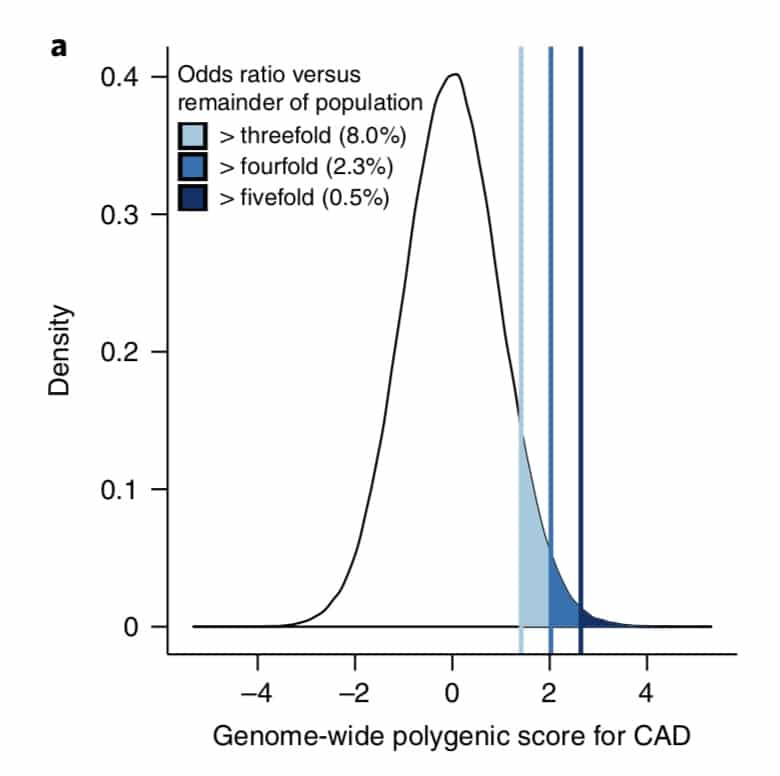
What is the clinical significance of residing within the tail of a distribution for disease risk? A new study published in Nature Genetics uses a composite polygenic score to measure extremes of genetic risk(see original article here). The authors make the bold statement: “it is time to contemplate the inclusion of polygenic risk prediction in clinical care”. In this plengegen.com blog, I briefly review the paper, frame the impact of the study in terms of “long tails”, and propose how genetic tails may be used as part of a healthcare system reimagined.
The premise of the paper is that a genome-wide polygenic score (GPS) – a composite genetic test that includes thousands and sometimes millions of genetic variants – can identify a small number of individuals from the general population that have an elevated risk. The study applies polygenic risk scores to five common diseases but spends most attention to coronary artery disease (CAD). For each disease, the increase in risk is approximately 3- to 5-fold higher among individuals at the extreme of the polygenic tail compared to those in the general population – see Figure 2a (and below) for CAD, where ~8% of the general population is at a 3-fold increase in risk based on a polygenic risk score.…
[Disclaimer: I am an employee of Celgene. The views reported here are my own.]
Drug research and development (R&D) is a slow, arduous process. As readers of this blog know, it takes >10 years and upwards of $2.5 billion dollars to bring new therapies to patients in need. An aspiration of the biopharmaceutical ecosystem is to shorten cycle times and increase probability of success, thereby dramatically improving the efficiency of R&D.
One potential solution is to use human genetics to pick targets, understand molecular mechanism, select pharmacodynamics biomarkers, and identify patients most likely to respond to treatment (see Science Translational Medicine article here). While intuitively appealing and supported by retrospective analyses (here), it is not yet routinely implemented in most R&D organizations (although see Amgen blog here; Regeneron study below). Indeed, human genetics often represents an inconvenient path to a new therapeutic, as it takes substantial effort to understand the molecular mechanism responsible for genetic risk and many such targets are difficult to drug.
But what if…
…it were possible to go from gene variant to therapeutic hypothesis instantly via in silico analysis;
…it were possible to select an “off-the shelf” therapeutic molecule that recapitulates a human genetic mutation, and take this molecule into humans almost immediately, with limited pre-clinical testing;
…it were possible to select pharmacodynamics (PD) biomarkers that capture underlying human physiology, and to measure those PD biomarkers in a small, human proof-of-mechanism clinical trial;
…it were possible to model the magnitude of effect of a therapeutic intervention relative to existing standard-of-care, and thereby to estimate the commercial market of an as-yet-to-be-approved drug?…
Over the holidays my family participated in an Escape Room, a live puzzle adventure game. We worked as a team to solve riddles, find clues and, over the course of 60-minutes, complete an old town bank heist. Many of the successful clues came from unexpected places – coordinates on maps, numbers inscribed in hidden places, and physical features of the room itself. Other clues seemed promising, but ultimately led to dead ends. In the end, everything came together and we escaped with only seconds to spare.
And so it goes with the invention of new medicines. The approval of a new medicine is an Escape Room of sorts, but over the course of decades not minutes. And like an Escape Room, clues can come from unexpected places, with some leading to new insights and others leading to dead ends.
I was in an Escape Room state-of-mind as I read a Science Translational Medicine article that developed a system to differentiate blood cells into microglia-like cells to study gene variants implicated in neurodegenerative disorders (here). In this blog, I provide a brief summary of the study, and then describe the potentially interesting phenomenon of genetically driven tissue-specific pathogenicity.…
A new genetics initiative was announced today: the creation of FinnGen (press release here). FinnGen’s goal is to generate sequence and GWAS data on up to 500,000 individuals with linked clinical data and consented for recall. There are many applications for such a resource, including drug discovery and development. In this blog, I want to first describe the application of PheWAS for drug discovery and development, and then introduce FinnGen as a new PheWAS resource (see FinnGen slide deck here).
[Disclaimer: I am an employee of Celgene. The views expressed here are my own.]
PheWAS
PheWAS turns GWAS on its head. While GWAS tests millions of genetic variants for association to a single trait, PheWAS does the opposite: tests hundreds (if not thousands) of traits for association with a single genetic variant. This approach is primarily relevant for those genetic variants with an unambiguous functional consequence – for example, a variant associated with disease risk or a variant that completely abrogates gene function. There are useful online resources (see here), as well as several nice recent reviews by Josh Denny and colleagues, which provide additional background on PheWAS (see here, here).
Work that originated from my academic lab represents the first example of PheWAS for drug discovery – in particular, how to use PheWAS to predict on-target adverse drug events (ADEs) and to select indications for clinical trials (see 2015 PLoS One publication here).…
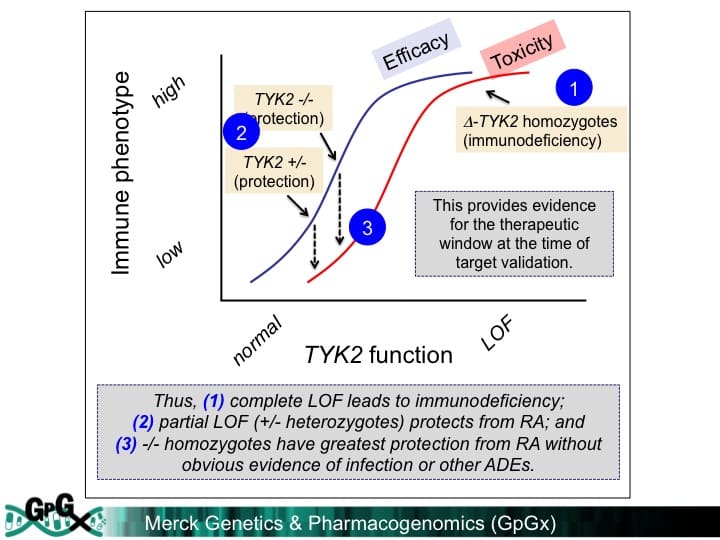
In response to an original research article published in Nature by Sekar Kathiresan and colleagues (see here), I penned a News & Views piece for Nature (here), a blog for the Timmerman Report (here, here), and a podcast for BBC Inside Science (here). An important theme for drug discovery & development is that human knockouts can rule-in and to rule-out drug targets.For human knock-out data, the key concept is to understand the effect of maximum genetic perturbation on human physiology.
Rule-in drug targets: As has been described by Matt Nelson and colleagues from GlaxoSmithKline (see 2015 Nature Genetics), and David Cook and colleagues from AstraZeneca (see 2014 Nature Reviews Drug Discovery), therapeutic molecules developed against targets with human geneticdata are more likely to lead to regulatory approval than those without.PCSK9 represents the poster child for human genetic knockouts in drug discovery & development (see my plengegen.com blog here).But there are many other examples, too.
Rule-out drug targets: But human genetics can also rule-out drug targets or mechanisms that are nominated through animal models, human epidemiology or other approaches.A prominent example is related to raising HDL cholesterol, the so-called “good cholesterol”.
Here are my thoughts on the Discussion Paper by Bernard H. Munos and John J. Orloff, “Disruptive Innovation and Transformation of the Drug Discovery and Development Enterprise” (download pdf here). This blog won’t make much sense if read out-of-context. Thus, I recommend reading the Discussion Paper itself, and using this blog as a companion guide at the completion of each section.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
STRENGTHS AND WEAKNESSES OF THE CURRENT INDUSTRY MODEL
In the near-term (10-years), I suspect that the pharma model of late development and commercialization will likely persist, as the cost and complexity of getting a drug approved is difficult by other mechanisms. Over time, however, new ways of performing late-stage trials will likely evolve. Drugs that are today in the early R&D pipeline will drive this evolution. If drugs look like they do today, dominated by small molecules and biologics with high probability of failure in Phase II/III, then the current model will likely continue with incremental improvements in efficiency. However, if new therapeutic modalities emerge (CRISPR, mRNA, microbiome, etc) and/or the probability of success in Phase II/III improves substantially, then the model of late development and commercialization will be forced to evolve, too.…
It has been a good week for human genetics, with high-profile studies published in Science (here) and NEJM (here, here, here), and a summit at the White House on Precision Medicine. Here, I summarize the published studies and put them in context for drug discovery. But first, I want to briefly detour into a story about the Wright Brothers.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
In 1900, Wilbur and Orville Wright first began experiments with their flying machine. They defined three problems for manned flight: power, wing structure and control. As described beautifully in David McCullough’s book (review here), the brothers focused on the latter, control, which when sufficiently solved led to the first manned flight in 1903. Within ten years of solving the “flying problem”, aviation technology progressed to the point that manned flights were routine.
By analogy, I would argue that there are three key challenges for drug discovery: targets, biomarkers and clinical proof-of-concept studies. The key problem to solve is target selection. Today, we do not know enough about causal human biology to select targets, and as a consequence we have a crisis in cost (drugs are too expensive to develop because of failures at the most costly stage, late development) and innovation (for those drugs that work, there is insufficient differentiation from standard-of-care treatments to change health care outcomes).…
A study published last week in Science described a large-scale genetic association study of Neandertal-derived alleles with clinical phenotypes from electronic health records (EHRs). Here, I focus less on the Neandertal aspect of the study – which to me is really just a gimmick and not medically relevant – and more on the ability to use EHR data for unbiased association studies against a large number of clinical traits captured in real-world datasets. I also provide some thoughts on how this same approach could be used for drug discovery.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
The study used clinical data from the Electronic Medical Records and Genomics (eMERGE) Network, a consortium that unites EHR systems linked to patient genetic data from nine sites across the United States. The clinical data was primarily from ICD9 billing codes, an imperfect but decent way to capture clinical data from EHRs. In total, a set of 28,416 adults of European ancestry from across the eMERGE sites had both genotype data and sufficient EHR data to define clinical phenotypes (n=13,686 in the Discovery set; n=14,730 in the replication set).…
I say article of the week, but I have been lazy this summer (or maybe just consumed by other things). My last “article of the week” was in May and my last Plengegen blog post was over a month ago!
By now everyone knows the PCSK9 story. Human genetics identified the target; functional work in mouse and human cells led to a mechanistic understanding of PCSK9’s role in LDL receptor recycling; therapeutic modulation was shown to lower LDL cholesterol in clinical trials; and the FDA approved drugs based on LDL lowering, with outcome trials underway to demonstrate (presumably) cardiovascular benefit. What the story highlights is that a mechanistic understanding of causal pathways in human disease is key to the success of translating targets into therapies. Further, the PCSK9 story underscores the importance of a simple biomarker (LDL cholesterol) to measure a complex causal pathway in a clinical trial.
If you could pick three innovations that would revolutionize drug discovery in the next 10-20 years, what would they be?
I found myself thinking about this question during a recent family vacation to Italy. I was visiting the Galileo Museum, marveling at the state of knowledge during the 1400-1600’s. The debate over planetary orbits seem so obvious now, but the disagreement between church and science led to Galileo’s imprisonment in 1633.
So what is it today that will seem so obvious to our children and grandchildren…and generations beyond? Let me offer a few ideas related to drug discovery, and hope that others will add their own. I am not sure if my ideas are grounded in reality, but that is part of the fun of the game. In addition, “The best way to predict the future is to invent it.”
To start, let me remind readers of this blog that I believe that the three major challenges to efficient drug discovery are picking the right targets, developing the right biomarkers to enable proof-of-concept (POC) studies, and testing therapeutic hypotheses in humans as quickly and safely as possible. Thus, the future needs to address these three challenges.
The primary purpose of this blog is to recruit clinical scientists into our new Translational Medicine department at Merck (job postings at the end). However, I hope that the content goes beyond a marketing trick and provides substance as to why translational medicine is crucial in drug discovery and development. Moreover, I have embedded recent examples of translational medicine in action, so read on!
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
There is a strong need to recruit clinical scientists into an ecosystem to develop innovative therapies that make a genuine difference in patients. This ecosystem requires those willing to toil away at fundamental biological problems; those committed to converting biological observations into testable therapeutic hypotheses in humans; and those who develop therapies and gain approval from regulatory agencies throughout the world. The first step is largely done in academic settings, and the other two steps largely done in the biopharmaceutical industry…although I am sure there are many who would disagree with this gross generalization!
The term “Translational Medicine” has been broadly used to describe the second step, thereby bridging the Valley of Death between the first and third steps.…
I admit upfront that this is a self-serving blog, as it promotes a manuscript for which I was directly involved. But I do think it represents a very nice example of the role of human genetics for drug discovery. The concept, which I have discussed before (including my last blog), is that there is a four-step process for progressing from a human genetic discovery to a new target for a drug screen. A slide deck describing these steps and applying them to the findings from the PLoS One manuscript can be found here, which I hope is valuable for those interested in the topic of genetics and drug discovery.
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer. However, the PLoS One study was performed while I was still in academics at BWH/Harvard/Broad.]
Before I provide a summary of the study, I would like to highlight a few recent news stories that highlight that the world thinks this type of information is valuable. First, the state of California is investing US $3-million in a precision medicine project that links genetics and medical records to develop new therapies and diagnostics (here, here).…
There was an eruption in Iceland last week. No, this was not another volcanic eruption. Rather, there was a seismic release of human genetic data that provides a glimpse into the future of drug discovery. The studies were published in Nature Genetics (the issue’s Table of Contents can be found here), with insightful commentary from Carl Zimmer / New York Times (here), Matthew Herper / Forbes (here), and others (here, here).
[Disclaimer: I am a Merck/MSD employee. The opinions I am expressing are my own and do not necessarily represent the position of my employer.]
As I have commented before, human genetics represent a very powerful approach to identify new drug targets (see here, here). I have articulated a 4-step process (see slide #5 from this deck): (1) select a phenotype that is relevant for drug discovery; (2) identify a series of genetic variants (or “alleles”) that is associated with the phenotype; (3) assess the biological function of phenotype-associated alleles; and (4) determine if those same alleles are associated with other phenotypes that may be considered adverse drug events.
There is an important assumption about this model: genes with an “allelic series” will be identified from large-scale genetic studies, and these phenotype-associated alleles will serve as an estimate of function-phenotype dose-response curves.…
ICYMI – the New England Patriots won the Super Bowl. How they did it was remarkable, and improbable. To introduce this week’s articles on human genetics and drug discovery, I want to focus on the interception of Russell Wilson by Malcolm Butler. If the pass is on-target, Seahawks win. By now you know the story: the pass was off-target, and the Seahawks lost.
[A lot has been said about Pete Carroll’s play call (see FiveThirtyEight.com statistical analysis here), but that is irrelevant for this discussion.]
As in football, on-target vs off-target events are highly relevant in drug discovery. Think about what it takes to develop a drug, and how “drug accuracy” (like passing accuracy) can make-or-break a development program. First, you start with a target. Next, you develop a drug against that target. Then, you test the target in pre-clinical models to make sure it is doing what you think it should do. And finally, you take the drug into humans to see if it has an adequate therapeutic index (i.e., is safe and effective).
All along the way you assess whether the therapeutic molecule is selectively engaging and modulating the desired target, and not acting more promiscuously on other targets in the system.…



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}